Classic Corpora in LDC’s Catalog: ACE
The objective of the Automatic Content Extraction (ACE) program was to develop the capability to extract meaning (entities, relations and events) from multimedia sources (Doddington, et al., 2004). LDC supported ACE by creating annotation guidelines, corpora and other linguistic resources, including training and test data for the common task research evaluations (Strassel, et al., 2003; Huang, et al., 2004).
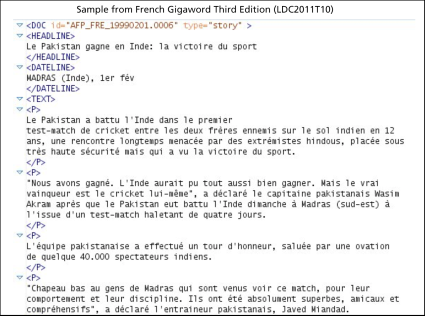
There are multiple data sets in LDC’s Catalog from the program. One that regularly makes the list of LDC’s top ten most licensed corpora is ACE 2005 Multilingual Training Corpus (LDC2006T06). This data set contains 1,800 files of mixed genre text in English, Arabic, and Chinese annotated for entities, relations, and events. The genres include newswire, broadcast news, broadcast conversation, weblog, discussion forums, and conversational telephone speech.
Another popular data set, ACE 2004 Multilingual Training Corpus (LDC2005T09), consists of varied genre text in English (158,000 words), Chinese (307,000 characters, 154,000 words), and Arabic (151,000 words) annotated for entities and relations.
ACE 2007 Multilingual Training Corpus (LDC2014T18) has the complete set of Arabic and Spanish training data for the 2007 ACE technology evaluation, specifically, Arabic and Spanish newswire data and Arabic weblogs annotated for entities and temporal expressions.
Other ACE corpora in the Catalog include ACE 2005 SpatialML Annotations in English and Mandarin (LDC2008T03, LDC2010T09, and LDC2011T02), Datasets for Generic Relation Extraction (reACE), TIDES Extraction (ACE) 2003 Multilingual Training Data, ACE-2 Version 1.0, ACE Time Normalization (TERN) 2004 English Training Data v 1.0 (TERN), and more.
For the full list of available ACE data, visit LDC’s Catalog and select the ACE research project in the search menu. For more information about linguistic resources for the ACE Program, including annotation guidelines, task definitions and other documentation, visit LDC's ACE webpage.