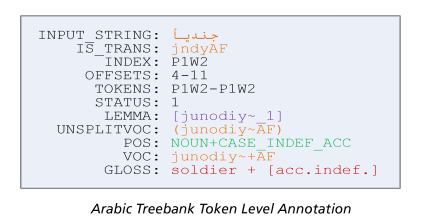
The Penn/LDC Arabic Treebank (ATB) project began in 2001 with support from the DARPA TIDES program and later, the DARPA GALE and BOLT programs. The original focus was on Modern Standard Arabic (MSA), not natively spoken and not homogenously acquired across its writing and reading community. In addition to the expected issues associated with complex data annotation, LDC encountered several challenges unique to a highly inflected language with a rich history of traditional grammar. LDC relied on traditional Arabic grammar, as well as established and modern grammatical theories of MSA -- in combination with the Penn Treebank approach to syntactic annotation -- to design an annotation system for Arabic. (Maamouri, et al., 2004). LDC was innovative with respect to traditional grammar when necessary and when other syntactic approaches were found to account for the data. LDC also developed a wide-coverage MSA morphological analyzer, LDC Standard Arabic Morphological Analyzer (SAMA) Version 3.1 (LDC2010L01), which greatly benefited ATB development. Revisions to the annotation guidelines during the DARPA GALE program (principally related to tokenization and syntactic annotation) improved inter-annotator agreement and parsing scores.
ATB corpora were annotated for morphology, part-of-speech, gloss, and syntactic structure. Data sets based on MSA newswire developed under the revised annotation guidelines include Arabic Treebank: Part 1 v 4.1 (LDC2010T13), Arabic Treebank: Part 2 v 3.1 (LDC0211T09) and Arabic Treebank: Part 3 v 3.2 (LDC2010T08). Other genres are represented in Arabic Treebank – Broadcast News v 1.0 (LDC2012T07) and Arabic Treebank – Weblog (LDC2016T02).
LDC’s later work on Egyptian Arabic treebanks in the DARPA BOLT program benefited from the strides in its MSA treebank annotation pipeline. As for the challenges presented by informal, dialectal material, collaborator Columbia University provided a normalized Arabic orthography to account for instances of Romanized script (Arabizi) in the data and developed a morphological analyzer (CALIMA) in parallel, working in a tight feedback loop with LDC’s annotation team. SAMA and CALIMA were synchronized in the Egyptian Arabic treebanks, the former used for MSA tokens and the latter used for Egyptian Arabic tokens. Resulting corpora include BOLT Egyptian Arabic Treebank – Discussion Forum (LDC2018T23), Conversational Telephone Speech (LDC2021T12), and SMS/Chat (LDC2021T17).
ATB corpora and its related releases are available for licensing to LDC members and nonmembers. For more information about licensing LDC data, visit Obtaining Data.